
40
दृश्य

झूठ का सबसे प्रभावी तरीकों में से एक - आँकड़ों की गलत व्याख्या। यह जानते हुए कि संख्या के साथ हथकंडा करने के लिए कैसे, अगर आप को धोखा देने की कोशिश नोटिस कर सकते हैं।
सांख्यिकीय आंकड़ों के संग्रह में पहला कदम - निर्धारित करने के लिए क्या आप विश्लेषण करना चाहते। इस स्तर पर सांख्यिकीविदों कॉल जानकारी माता-पिता की आबादी. तो फिर तुम डेटा का एक उपवर्ग, जो विश्लेषण में एक पूर्ण रूप में आबादी का प्रतिनिधित्व करना चाहिए निर्धारित करने होंगे। बड़े और अधिक सटीक नमूना, अधिक संभावना है कि अध्ययन के परिणाम हो जाएगा।
बेशक, वहाँ गलती से या जानबूझकर एक सांख्यिकीय नमूना खराब करने के लिए अलग अलग तरीके हैं:
त्रुटि नमूने की सुंदरता है कि किसी को कहीं न कहीं शायद एक अवैज्ञानिक सर्वेक्षण है कि अपने सिद्धांत के किसी भी पुष्टि करेगा रखती है। इसलिए वेब पर सही सर्वेक्षण के लिए देख सकते हैं या अपना खुद का बना।
चूंकि आंकड़े नंबर का उपयोग कर, हमें विश्वास है कि यह किसी भी विचार साबित होता है। जटिल गणितीय आधार पर सांख्यिकी कंप्यूटिंगजो अगर ठीक से नहीं संभाला काफी विपरीत परिणाम मिल सकते हैं।
त्रुटिपूर्ण डेटा विश्लेषण प्रदर्शन करने के लिए, अंग्रेजी गणितज्ञ फ्रांसिस Anscombe बनाया Anscombe की चौकड़ी. यह संख्यात्मक आंकड़ों के चार सेट के होते हैं में रेखांकन काफी अलग ढंग से करते हैं।
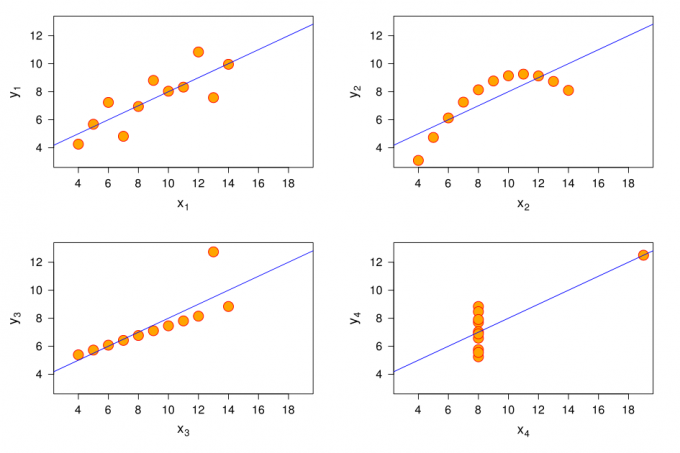
आंकड़ा X1 - एक मानक scatterplot; X2 - वक्र जो शुरू में बढ़ जाता है, और फिर नीचे की ओर गिर जाता है; X3 - लाइन से थोड़ा एक के लिए बढ़ जाता है रिहाई Y अक्ष पर; X4 - अक्ष एक्स पर डेटा है, लेकिन एक उत्पादन, दोनों धुरियों पर उच्च स्थित है।
निम्नलिखित बयानों में से प्रत्येक के लिए रेखांकन का सच कर रहे हैं:
हम केवल कुछ के रूप में डेटा को देखते हैं, हम, सोच सकता है कि स्थिति पूरी तरह से एक ही है, हालांकि ग्राफिक्स इससे इनकार करते हैं।
इसलिए Anscombe पहले कल्पना डेटा का सुझाव दिया, और उसके बाद ही निष्कर्ष निकालना। बेशक, अगर आप त्रुटि में किसी परिचय करना चाहते हैं, इस कदम को छोड़।
अधिकांश लोगों को अपने स्वयं के सांख्यिकीय विश्लेषण का संचालन करने के लिए समय नहीं है। वे उम्मीद करते हैं कि आप उन्हें चार्ट आपके द्वारा अनुसंधान के सभी का सारांश दिखा। ठीक तरह से समय निर्धारण कि अनुरूप वास्तविकता के विचारों को प्रतिबिंबित करना चाहिए। लेकिन वे भी डेटा है कि आप दिखाना चाहते हैं पर जोर कर सकते हैं।
कुछ मानकों के नाम कम से थोड़ा अक्ष पर पैमाने बदलने के लिए, संदर्भ की व्याख्या नहीं है। तो अगर आप अपने सच्चाई का हर किसी को समझाने के लिए सक्षम हो जाएगा।
आप अपने स्रोत निर्दिष्ट खोलते हैं, तो लोगों को आसानी से अपने निष्कर्ष का परीक्षण करें। बेशक, अगर आप अपनी उंगली के आसपास के गोले सब करने का लक्ष्य है मुझे बता नहीं होगा कि कैसे आप अपने निष्कर्ष के लिए आया था।
आमतौर पर, लेख और पढ़ाई में हमेशा सूत्रों के संदर्भ संकेत मिलता है। इस मामले में, मूल काम पूरी तरह से नहीं प्रदान की जा सकती। मुख्य बात यह है कि स्रोत निम्न सवालों के जवाब दिए है:
अब आप संख्या में हेरफेर करने के लिए कैसे और आंकड़ों का उपयोग लगभग कुछ भी साबित करने के लिए पता है कि। यह आपको समझते हैं और खंडन झूठ सिद्धांत गढ़े में मदद मिलेगी।